
Sent from my ipod
Big-O Analysis For Recreational Programmers
Part of why I write these technical posts is to get a better understanding of a topic. You ask why I can’t do this without writing it as as a blog post? It’s like when you clean your house when you know you have guests coming. You could clean all the time, but you don’t.
Computing theory is hard to grasp unless it is laid out in concrete examples. I had a tough time understanding Big-O analysis in school. A self taught programmer who I met at Hacker Hours asked to explain big-O analysis and I asked him for a week to write this post. So here is my attempt at demystifying it - in plain English. This is not a theoretical post. I don’t claim to know all the theory behind big-O analysis. This is simply a way of understanding the fundamentals without getting bogged down by academic lingo, formulae and greek letters.
Performance analysis vs big-O analysis
We have all heard about performance. It is the amount of time taken by a certain task. The task could consist of a single operation or a hundred operations. The performance could depend on a lot of different factors like the machine we run it on, the programming language environment, network latency, etc.
Big-O analysis is not the same as performance analysis. Big-O analysis is useful in figuring out the best algorithm for a task at hand. But how do we define “best algorithm”? And what is an algorithm anyway?
Simply put, an algorithm is a way to solve a problem. Big-O analysis will help us understand how well an algorithm will scale in the worst-case scenario. This allows us to compare two different algorithms solving the same problem.
Reasonable parameters to consider if the algorithm is good can be measured with two factors :
- How much time is spent performing operations? (We will define an ‘operation’ below). Also known as time complexity.
- How much memory does it occupy on a machine? Also known as space complexity.
We will avoid considering the space complexity for this discussion and as do most people when talking about big-O analysis.In the rest of my post, complexity == time complexity.
In a loose sense, performance is useful in measuring absolute time spent on a certain task. However, big-O analysis is about relative time spent by the algorithm to solve the problem, thus leveling the playing field.
Let’s say we are given some unsorted numbers and we need to arrange them in ascending order. As you probably already know, there are many ways to sort those numbers. Let’s look at two simple sorting techniques, sorting the same input numbers :
If you just arrived to the show below, simply refresh the page and it will start from the beginning :)
Merge Sort
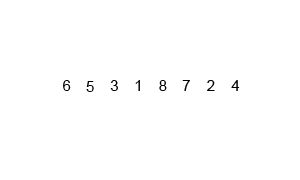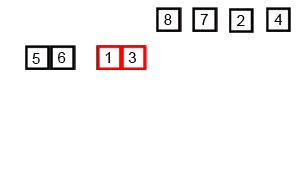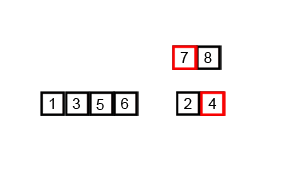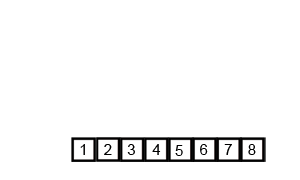
Insertion Sort
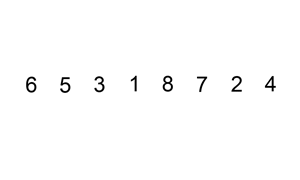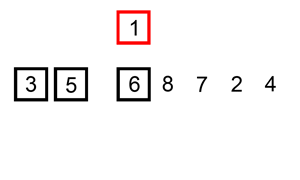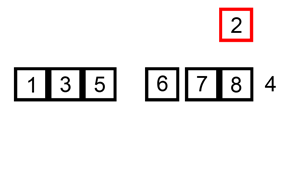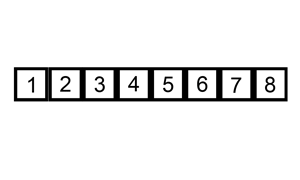
Animation source: Wikipedia
As we can see, the number of operations performed on the set of numbers is different in each case. Depending on the input sequences and the size of these numbers, one algorithm relatively performs better than the other.
Representation
The output to a big-O analysis is always, surprise, a big ‘O’ followed by parentheses. Within the parentheses is expression in terms of ‘n’ or the number 1.
What goes into the parentheses is determined by the factors below.
Big ideas of big-O analysis
There are 3 main ideas we need to think about when performing big-O analysis of an algorithm:
Input
The input is directly correlated to the complexity. Depending on what the input is and the operations we need to perform on it, the complexity of the algorithm can be different in the best, worst and average case. For example, in case of the sorting a set of unsorted numbers, the complexity of the algorithm will depend on the size of the input. The best case scenario for any sorting problem is to have an input that is already sorted. In the animations above, notice how insertion sort will be faster than merge sort in the best case scenario because merge sort will need to divide the list of numbers into a size of 1, regardless. Insertion sort on the other hand will make only a single pass through all the elements. Similarly, the complexity might vary in the best or average case for different algorithms depending on how the algorithm is implemented.
Operation
An operation could be an iteration of a for-loop or could be as simple as returning the first element of a list, regardless of the size of the list. In case of the for-loop, if the number of iterations we perform is the same as the size of the input, the algorithm is said to have a complexity of O(n). In the case where the operation returns the first element of the input, the size of the input doesn’t matter. The number of operations performed is always 1. This is known as constant complexity and represented as O(1).
Ignoring lower order terms
When performing big-O analysis, we ignore the lower order terms and constants. Consider an algorithm that performs the following operations: A nested for-loop where both loops iterate over all the elements passed in as input, a while-loop which iterates over all the elements passed in as input and a simple operation to add two numbers. The complexity in this case will be O(n^2 +n+1).
The complexity is O(n^2) because we need to eliminate the lower order terms and constants. The reason of this is, when stating the complexity of the algorithm, we always assume that the input is a large number of values. When ‘n’ tends to become large, the constants and the terms with lower powers tend to matter less. This is purely by convention and there is no reason we cannot design an algorithm for only a small set of input values, if we are sure about it.
Note that if we have our operation calling another function, then the complexity of the algorithm will need to include the complexity of that algorithm as well.
Here are some Java examples to solidify the concept.
Big-O Examples
Constant
Representation : O(1)
Code :
1
2
3
4
5
6
7
8
// Checks if the first Character of an array is the character 'A'
private static boolean isFirstCharA(char [] chars){
if(chars[0] == 'A')
return true;
else
return false;
}
Explanation :
It doesn’t matter what the size of the input array is, the only operation that the function (algorithm) performs is to check if the first element is ‘A’. Hence regardless of the input size, the complexity is O(1).
Linear
Representation : O(n)
Code :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// Finds the largestNumber in the given input integer array
private static int findLargestNumber(int[] input ) {
int largestNumber = 0;
for(int current:input){
if(current > largestNumber){
largestNumber = current;
}
}
return largestNumber;
}
Explanation :
Regardless of where the largest number is in the input integer array, the algorithm needs to traverse all the elements of the array at least once. Hence, considering we have ‘n’ elements, the complexity is O(n).
Polynomial
Representation : O(n^2)
Code :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// Checks if there any number in one array is equal to another
private static boolean checkIfDuplicatesExist(int[] input1, int[] input2) {
for (int currentInput1 : input1) {
for (int currentInput2 : input2) {
if (currentInput1 == currentInput2) {
return true;
}
}
}
return false;
}
Explanation :
Notice that there are two for-loops in the above algorithm. O(n^2) complexities appear in cases where there are nested loops. This type of complexity is called polynomial and O(n^2) is specifically known as quadratic complexity. Beginners often come to a conclusion that the number of loops in the algorithm dicates the complexity. This has been true in the case of linear and polynomial complexity, but will be not be true in the case of logarithmic analysis, as we will see next.
Logarithmic
Representation : O(log n)
Code :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// Checks the number of times a given number can be divided by 2 before we end up with a remainder of 1 or less.
private static int divideByTwo(int input){
int counter = 0;
while(input > 1){
input = input/2;
counter++;
}
return counter;
}
Explanation :
When we give this function an input of ‘64’, the number of times the while loop runs is 6. Coincidentally, the log base 2 of 64 = 6. As we progress through the problem, the number of steps required to reach the end is not linear anymore. It reduces logarithmically. Log n complexities are a good thing.
Factorial
Representation : O(n!)
Explanation :
A great example for the factorial complexity is the traveling salesman problem. Let’s say there are 3 towns (which are all at different distances from each other) a salesman needs to visit and the problem is to figure out the shortest path to visit all three towns. If we write down the different paths, we will come up with 6 paths, which is nothing but 3! where 3 is the number of towns :
A -> B -> C
A -> C -> B
B -> C -> A
B -> A -> C
C -> A -> B
C -> B -> A
For an input of n, the complexity of such a problem will be O(n!). Note that half of paths in this case will be of the same distance, just traversed in reverse, so technically the complexity should be O(n!/2). However, remember that we ignore all constants while coming up with the complexity.
Exponential
Representation : O(2 ^n)
Explanation :
Algorithms where the number of operations required to solve the problem increases exponentially have a complexity of O(2^n). Similar to the factorial complexity, as n tends to be very large, the problems cannot be solved in a reasonable amount of time. For example, a program where n=30 could result in 1 billion operations.
That’s it folks. This post barely skims the surface of all that is possible in algorithm analysis, but I will consider this a success it helps you in the future to do some rough analysis when comparing different approaches to solve a programming problem.
Let me know if I can describe anything better or if you feel like I have misrepresented anything here. A gist of all the code with some poor man’s tests available here.